
In the rapidly evolving world of artificial intelligence, Llama 3.2 stands out as a groundbreaking model that bridges the gap between visual and textual understanding. This powerful AI system, developed by Meta, represents a significant leap forward in multimodal AI capabilities. Let's dive deep into what makes Llama 3.2 so special and explore its potential to transform various industries.
Unparalleled Visual-Language Integration
At its core, Llama 3.2 excels in integrating visual and language processing, offering a range of applications that were once the stuff of science fiction. Here are some of the key areas where Llama 3.2 shines:
1. Visual Question Answering (VQA) and Visual Reasoning
Imagine showing a complex image to an AI and asking it detailed questions about what it sees. That's exactly what Llama 3.2 can do. Whether it's analyzing a busy street scene or a scientific diagram, this model can understand the content and context of images, answering questions with remarkable accuracy.
For instance, you could show Llama 3.2 a photograph of a bustling farmers market and ask, "How many different types of fruit can you see?" or "What's the predominant color of the vendor stalls?" The model would analyze the image, identify the various elements, and provide a thoughtful response.
2. Document Visual Question Answering (DocVQA)
Taking visual understanding a step further, Llama 3.2 can comprehend complex documents that combine text, images, and layouts. This capability is particularly valuable for industries dealing with large volumes of visual documents.
For example, in the legal sector, Llama 3.2 could analyze contracts, identifying key clauses and their relationships to visual elements like signatures or stamps. In healthcare, it could interpret medical charts, understanding both the written notes and visual data like X-rays or ECG readouts.
3. Image Captioning
Llama 3.2's ability to generate descriptive captions for images is nothing short of impressive. This goes beyond simple object recognition – the model can understand context, emotions, and subtle details in images, translating visual information into rich, accurate textual descriptions.
This capability has enormous potential in fields like journalism, where it could assist in quickly generating captions for large volumes of images. It could also be invaluable in making visual content more accessible to visually impaired individuals by providing detailed audio descriptions of images.
4. Image-Text Retrieval
Think of this as a super-smart, visual search engine. Llama 3.2 can match images with relevant text descriptions and vice versa. This capability could revolutionize how we organize and search through vast databases of images and documents.
In e-commerce, for instance, this could enable more intuitive product searches. A user could upload an image of a piece of furniture they like, and the system could find similar items in the inventory, complete with detailed descriptions.
5. Visual Grounding
This fascinating capability allows Llama 3.2 to connect specific parts of an image with textual descriptions. It's like giving the AI the ability to point at exactly what you're talking about in a picture.
In educational settings, this could be used to create interactive learning materials. Imagine a biology textbook where students can ask the AI to highlight specific parts of a cell diagram just by describing what they're looking for.
Beyond Direct Applications: Enhancing AI Development
What's particularly exciting about Llama 3.2 is its potential to accelerate AI development across the board. The model can be used for:
- Synthetic Data Generation: In fields where real-world data is scarce or sensitive (like healthcare), Llama 3.2 could generate realistic, diverse datasets for training other AI models.
- Model Distillation: The knowledge packed into Llama 3.2 can be transferred to smaller, more efficient models. This process, known as distillation, could lead to more deployable AI solutions in resource-constrained environments.
The Future of Visual-Language AI
As we look to the future, the potential applications of models like Llama 3.2 seem boundless. From enhancing autonomous vehicles' understanding of their environment to creating more intuitive and accessible user interfaces, the integration of visual and language AI is set to transform numerous aspects of our daily lives and various industries.
Llama 3.2 represents a significant milestone in this journey. By bridging the gap between what machines see and what they can communicate, it opens up new possibilities for human-AI interaction and problem-solving. As researchers and developers continue to explore and expand upon its capabilities, we can expect to see even more innovative applications emerge, pushing the boundaries of what's possible in the realm of artificial intelligence.
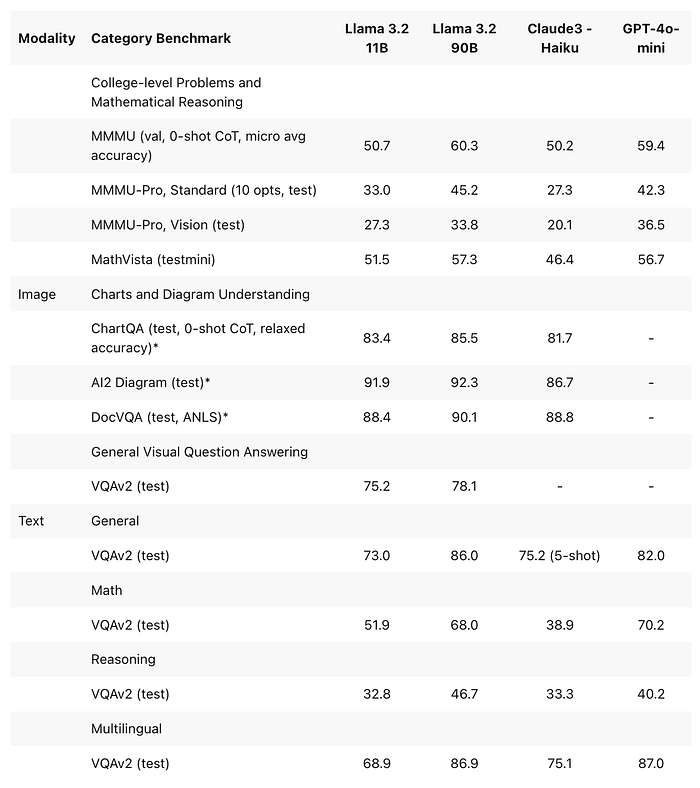
Comparison:
In conclusion, Llama 3.2 is not just another AI model – it's a glimpse into a future where machines can truly see, understand, and communicate about the visual world in ways that are remarkably human-like. As we continue to explore and harness its potential, we're bound to unlock new realms of possibility in the ever-evolving landscape of artificial intelligence.
